
Chặn bot crawl URL filter WooCommerce: hiểu đúng nguyên nhân để giảm tải mà không chặn nhầm
Vấn đề cốt lõi không nằm ở một vài request lẻ. Nó nằm ở chỗ URL filter có thể tạo ra số tổ hợp gần như vô hạn, khiến bot liên tục sinh thêm biến thể mới, kéo theo nhiều request khó cache, nhiều truy vấn nặng và nhiều lần render không cần thiết ở tầng ứng dụng.
Bài gốc nêu rất đúng một hiện tượng đang gặp nhiều ở website WooCommerce: server tăng CPU, chậm, thậm chí trả 503 khi bot liên tục truy cập các URL chứa tham số dạng ?filter_. Tuy nhiên, để xử lý bền hơn, cần tách vấn đề thành hai lớp khác nhau. Lớp thứ nhất là giảm tải ngay bằng challenge hoặc block có điều kiện. Lớp thứ hai là kiểm soát crawl và chuẩn hóa URL faceted navigation để không tiếp tục tạo ra một không gian URL quá lớn cho bot quét mãi không hết.
Điểm người quản trị hay nhầm là chỉ nhìn chuỗi User-Agent rồi quyết định cho qua hoặc chặn. Trên thực tế, User-Agent rất dễ bị giả mạo. Nếu xử lý chỉ bằng cách “thấy chữ Googlebot thì bỏ qua”, bạn có thể đang mở cửa cho bot giả. Ngược lại, nếu chặn cứng quá rộng, bạn lại có thể làm hỏng preview chia sẻ hoặc ảnh hưởng việc thu thập dữ liệu hợp lệ. Vì vậy, bài này bám sát giải pháp trong bài gốc, nhưng đi sâu hơn vào mặt kỹ thuật để làm rõ khi nào nên challenge, khi nào nên block, và đâu là phần nên xử lý ở cấp SEO/crawl thay vì chỉ xử lý ở firewall.
Tóm tắt nhanh
- URL filter kiểu ?filter_ có thể tạo ra rất nhiều biến thể, khiến bot sinh thêm request gần như vô hạn.
- Vấn đề lớn nhất không chỉ là băng thông, mà là số lần render và truy vấn ứng dụng cho các URL ít giá trị kinh doanh và ít giá trị tìm kiếm.
- Giải pháp trong bài gốc là đúng theo hướng ứng cứu nhanh: LiteSpeed verifycaptcha, LiteSpeed 403, hoặc Cloudflare custom rule.
- Ở mức chuyên môn sâu hơn, đừng chỉ tin User-Agent “Googlebot”; cần xác minh bot thật bằng reverse DNS hoặc cơ chế bot verification phù hợp.
- Với traffic giống trình duyệt thật, Managed Challenge thường an toàn hơn block cứng trong giai đoạn đầu tinh chỉnh rule.
- Giải pháp dài hạn là giảm crawl vào faceted URLs bằng robots.txt, canonical, chuẩn hóa thứ tự tham số và trả 404 cho tổ hợp lọc vô nghĩa hoặc không có kết quả.
Bài toán thực sự là gì?
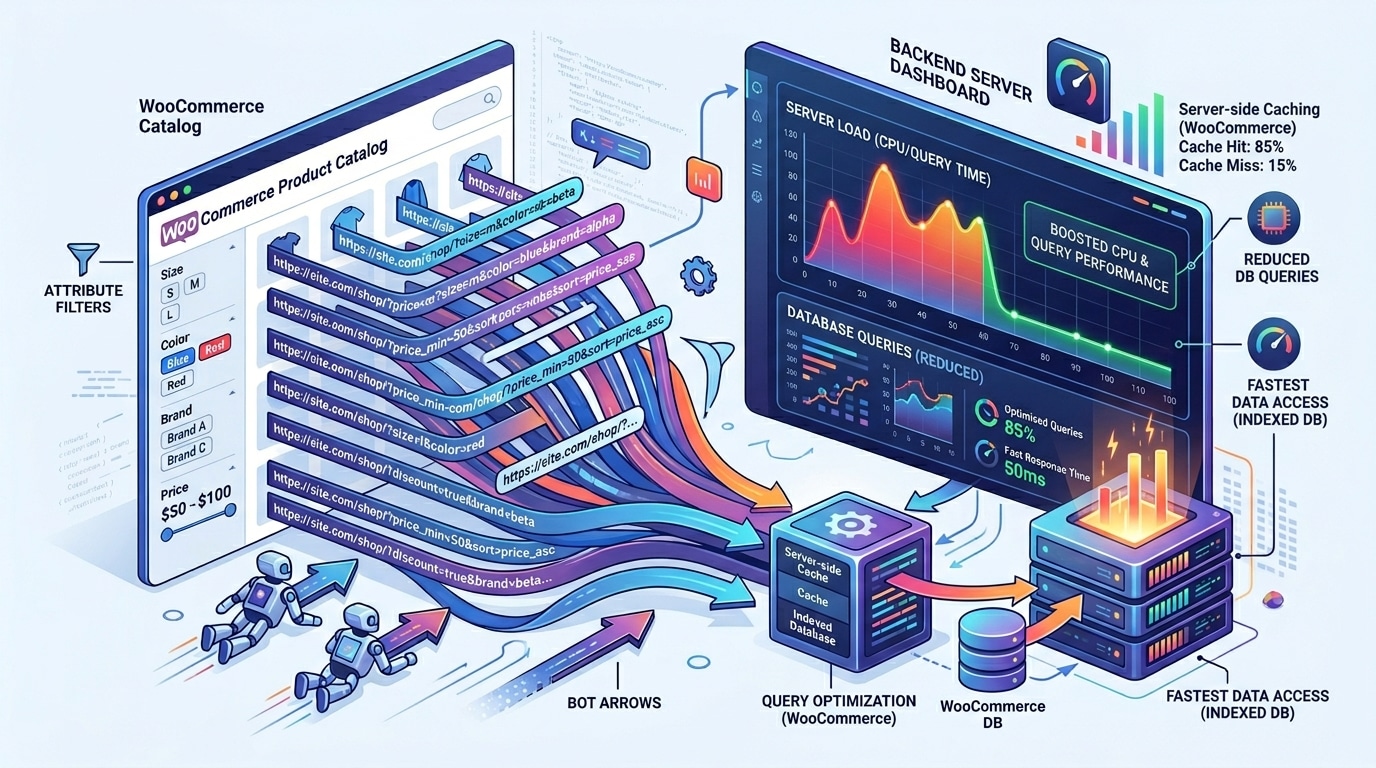
Khi người dùng lọc sản phẩm theo kích thước, màu sắc, thương hiệu hoặc nhiều thuộc tính cùng lúc, website thường sinh URL có query string. Chỉ cần thay đổi thứ tự giá trị, thêm một thuộc tính mới hoặc đổi một tổ hợp nhỏ, bot đã có thêm một URL để thử. Nếu hệ thống không chuẩn hóa mạnh, số URL tiềm năng tăng rất nhanh.
Đây là chỗ cần nhìn vấn đề theo ngôn ngữ kỹ thuật thay vì chỉ nhìn bằng cảm giác “bot vào nhiều”. Mỗi URL filter mới có thể kích hoạt cả một chuỗi xử lý: parse query string, khởi tạo truy vấn sản phẩm, tính taxonomy hoặc meta query, dựng fragment hiển thị, gọi object cache, truy vấn database và trả HTML. Nếu cache không bám tốt vào từng biến thể, hoặc bot liên tục sinh ra tổ hợp mới chưa từng được cache, origin sẽ phải làm lại công việc này liên tục.
“Moment of clarity” ở đây là: website không chậm vì chỉ có nhiều bot, mà chậm vì bot đang đẩy ứng dụng vào một vùng URL có độ biến thiên quá lớn. Càng nhiều biến thể mới, tỉ lệ cache hit càng thấp và chi phí xử lý trung bình trên mỗi request càng cao.
Vì sao URL filter WooCommerce đặc biệt dễ gây quá tải?
Không phải mọi request đều tốn tài nguyên như nhau. Với trang sản phẩm tĩnh hoặc danh mục chuẩn, cache thường phát huy tốt và bot hay người dùng đều chạm vào một số URL lặp lại. Nhưng với filter URL, bot có thể thử hàng loạt tổ hợp ít lặp lại: thêm thuộc tính, đổi thứ tự giá trị, đổi nhiều bộ lọc cùng lúc, hoặc tiếp tục theo các liên kết lọc mà giao diện tạo ra.
Ở tầng SEO, Google gọi hiện tượng này là faceted navigation và cảnh báo rằng kiểu điều hướng dựa trên URL parameters có thể tạo ra “infinite URL spaces”, dẫn tới overcrawling, làm chậm việc phát hiện URL hữu ích và tiêu tốn nhiều tài nguyên máy chủ. Nếu bạn không thực sự cần các URL filter này được index, việc để bot tự do crawl chúng thường mang lại rất ít lợi ích so với chi phí vận hành phải trả.
Hiểu ngắn gọn: filter URL hữu ích cho trải nghiệm lọc sản phẩm của người dùng, nhưng không mặc định có nghĩa là từng tổ hợp filter đều đáng để search engine hoặc các crawler khác ghé thăm liên tục.
Dấu hiệu nhận biết trong log và ở tầng ứng dụng
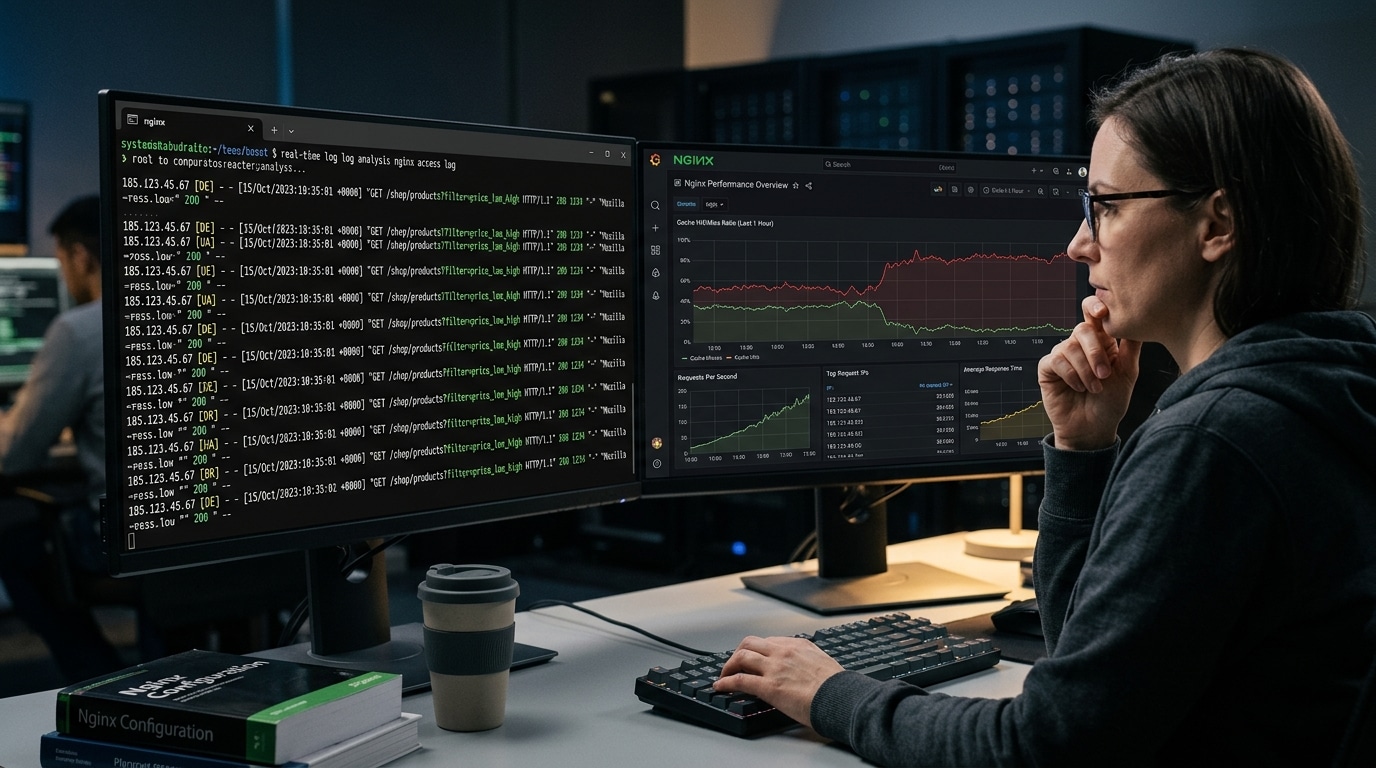
Bài gốc nêu bốn tín hiệu nhận biết rất thực tế: log có nhiều request chứa ?filter_, User-Agent giống trình duyệt thật, IP quốc tế và tần suất rất cao. Đó là dấu hiệu tốt để phát hiện sớm.
Tuy nhiên, đi sâu hơn một chút, bạn nên nhìn thêm ba nhóm dữ liệu nữa. Một là độ đa dạng query string: cùng một đường dẫn danh mục nhưng thay đổi tham số liên tục. Hai là cache outcome: nếu tỷ lệ MISS hoặc BYPASS cao bất thường ở nhóm URL filter, áp lực đang dồn về origin. Ba là query cost ở tầng PHP/MySQL: CPU php-fpm tăng, số truy vấn sản phẩm theo taxonomy hoặc meta tăng, và thời gian phản hồi nhóm URL này dài hơn hẳn trang thường.
grep -E '\?filter_' /var/log/nginx/access.log | awk '{print $1, $7, $12}' | head -200
grep -E '?filter_' /var/log/nginx/access.log | cut -d' ' -f7 | sort | uniq -c | sort -nr | head -50
grep -E '?filter_' /var/log/nginx/access.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -30Điều quan trọng là đừng dừng ở việc “thấy nhiều request”. Hãy kiểm tra xem chúng có đang tạo ra nhiều URL gần như duy nhất hay không. Nếu có, bạn đang đối mặt với crawl explosion chứ không đơn thuần là một bot ghé thăm hơi nhiều.
Giải pháp trong bài gốc: đúng cho ứng cứu nhanh, nhưng cần hiểu rõ phạm vi
Bài gốc đi theo ba hướng rất rõ ràng. Một là LiteSpeed dùng verifycaptcha khi query string chứa filter_, loại trừ IP Việt Nam và chuỗi Googlebot. Hai là chặn cứng 403 với điều kiện tương tự. Ba là đưa logic này lên Cloudflare bằng custom rule. Đây là các biện pháp giảm tải rất thực dụng vì chúng cắt request trước khi origin phải xử lý sâu hơn.
Về mặt kỹ thuật, hướng này hoàn toàn hợp lý nếu mục tiêu là hạ nhiệt server ngay. LiteSpeed hỗ trợ rewrite directive [E=verifycaptcha] để chuyển client sang cơ chế challenge, và cũng hỗ trợ các biến thể như deny hoặc drop trong cùng họ hành động. Cloudflare cũng cho phép tạo custom rules dựa trên các trường của request và thực hiện các hành động như Block hoặc Managed Challenge.
Nhưng đây là chỗ cần nói rõ ranh giới: các rule này giải quyết triệu chứng rất nhanh, chứ chưa giải quyết tận gốc việc website đang tạo ra một không gian faceted URLs quá rộng cho crawler đi vào. Vì vậy, chúng rất phù hợp để ứng cứu, còn phần triệt để phải nằm ở quản lý crawl và thiết kế URL.
Challenge hay 403: nên chọn cách nào trước?
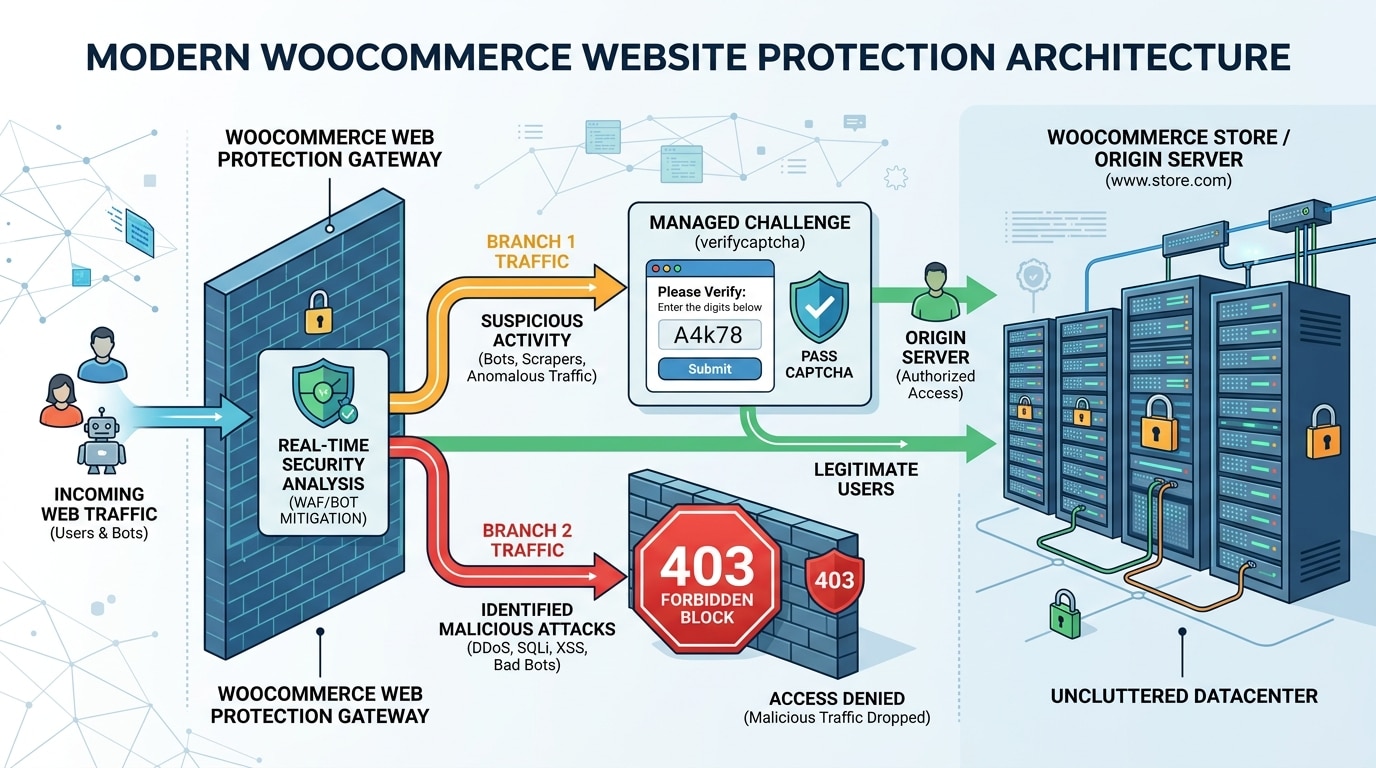
Nếu bạn chưa đo đủ dữ liệu và traffic xấu vẫn đang đội lốt trình duyệt thật, challenge thường là bước đầu an toàn hơn block cứng. Lý do là request vẫn bị chặn lại khỏi origin ở mức đáng kể, nhưng bạn giảm rủi ro chặn oan một số trình duyệt hợp lệ, đặc biệt trong giai đoạn còn tinh chỉnh biểu thức hoặc danh sách ngoại lệ.
Cloudflare hiện khuyến nghị Managed Challenge cho phần lớn WAF rules thay vì dùng kiểu challenge cứng cáp hơn trong mọi trường hợp. Cách tiếp cận này hợp lý với bài toán filter URL vì rất nhiều request xấu nhìn bề ngoài giống browser traffic. Với LiteSpeed, verifycaptcha cũng là cùng một triết lý: xác thực trước, rồi mới cho đi tiếp.
Ngược lại, nếu bạn đã xác nhận rõ mẫu traffic xấu, thấy origin đang quá tải nặng, và nhóm URL đó không có lý do kinh doanh hoặc SEO để được truy cập tự do từ quốc tế, chặn 403 có thể là lựa chọn phù hợp hơn. Cách nào đúng phụ thuộc vào mức khẩn cấp và độ chắc của tín hiệu bạn đã thu thập được.
Điểm chuyên môn quan trọng nhất: đừng chỉ whitelist theo chữ “Googlebot”
Đây là phần cần chỉnh góc nhìn so với cách triển khai nhanh trong bài gốc. Dùng điều kiện HTTP_USER_AGENT !Googlebot là tiện, nhưng chưa đủ chắc về mặt an toàn. Google nói rất rõ rằng User-Agent có thể bị spoof, và cách tốt nhất để xác minh yêu cầu có thực sự đến từ Googlebot hay không là reverse DNS rồi forward DNS đối chiếu lại IP.
Nói cách khác, chuỗi “Googlebot” chỉ nên được xem là một tín hiệu yếu. Nếu bạn miễn trừ rule chỉ vì thấy chuỗi này, bot giả hoàn toàn có thể đi qua. Trên Cloudflare, nếu có công cụ bot verification phù hợp, nên ưu tiên cơ chế verified bot thay vì chỉ so khớp chuỗi User-Agent. Ở origin, nếu bạn đang điều tra log thủ công, hãy xác minh IP của bot quan trọng trước khi đưa vào allowlist.
host 66.249.66.1
host crawl-66-249-66-1.googlebot.com“Moment of clarity” ở đây là: miễn trừ cho bot thật là đúng, nhưng miễn trừ theo User-Agent thuần túy thì chưa phải miễn trừ cho bot thật, mà là miễn trừ cho bất kỳ ai tự xưng là bot thật.
Meta crawler, SEO bot và bot giả trình duyệt: nên phân biệt thế nào?
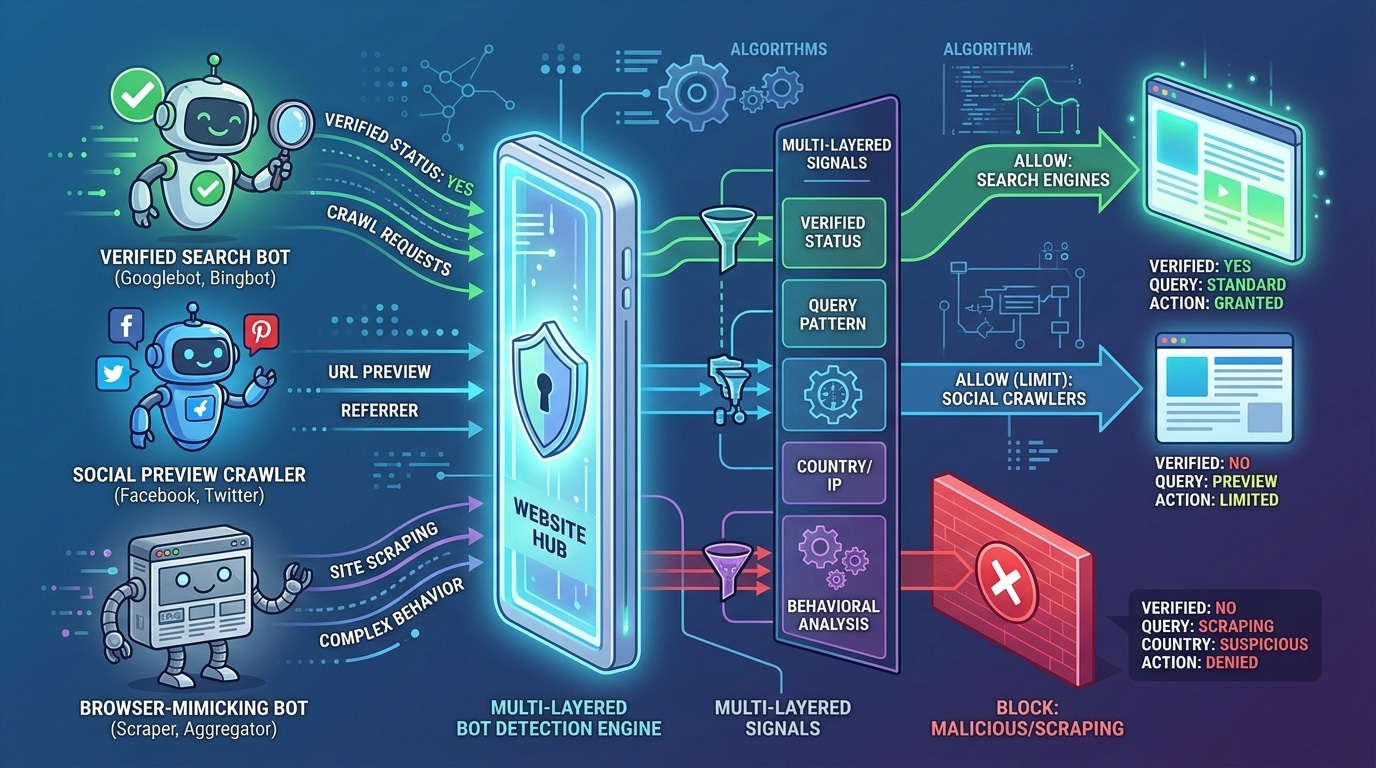
Bài gốc nhắc tới crawler của Meta, SEO bot và bot giả lập trình duyệt. Cách nhìn này đúng ở mức vận hành, nhưng khi đi vào policy, bạn nên tách nhóm bot theo tác dụng thực tế. Ví dụ, crawler của Meta tồn tại để fetch nội dung website được chia sẻ trên các ứng dụng của Meta nhằm tạo preview. Nếu bạn chặn quá rộng, chia sẻ link có thể mất ảnh đại diện hoặc mô tả.
Vì vậy, cách làm an toàn hơn là chặn hoặc challenge theo mẫu URL gây hại, thay vì phản ứng cảm tính với toàn bộ bot của một nền tảng. Với bài toán đang bàn, trọng tâm nằm ở URL filter chứ không phải ở mọi trang. Nếu product page, category chuẩn hoặc bài viết vẫn cần được preview và thu thập hợp lệ, rule nên nhắm đúng nhóm filter URL và đúng kiểu traffic gây tải.
Đây cũng là lý do tại sao bài toán này nên được xử lý bằng điều kiện ghép: query string, quốc gia, verified bot, kiểu endpoint và có thể thêm rate. Chỉ dùng một tín hiệu đơn lẻ thường hoặc quá lỏng, hoặc quá tay.
Giải pháp dài hạn: xử lý ở lớp crawl governance, không chỉ ở lớp chặn
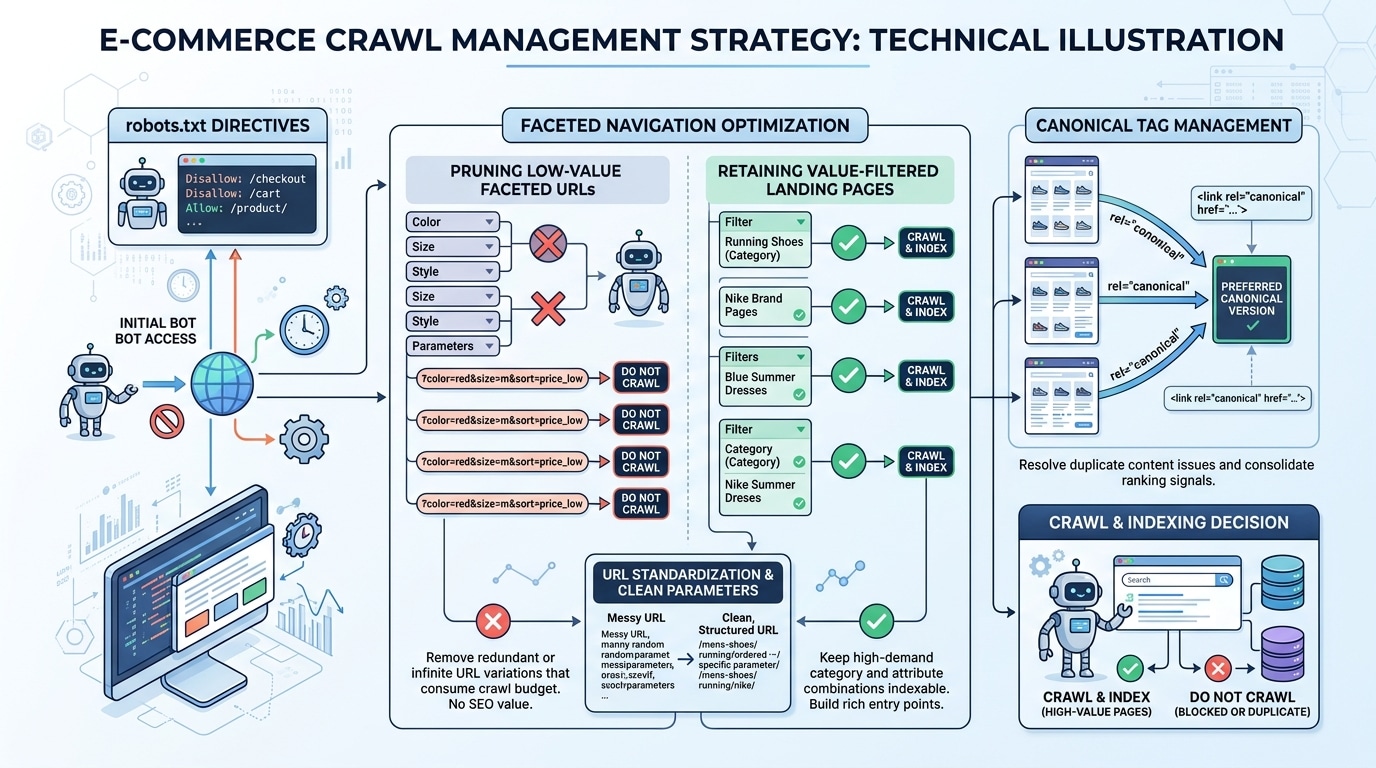
Nếu website không cần các URL faceted này xuất hiện trong kết quả tìm kiếm, hướng bền vững nhất là giảm quyền crawl của chúng. Google khuyến nghị dùng robots.txt để chặn crawling với các faceted navigation URLs không cần được index. Google cũng lưu ý rằng nếu vẫn muốn các URL faceted có thể được crawl, bạn nên chuẩn hóa mạnh: dùng đúng dấu phân tách tham số, giữ thứ tự logic của filter luôn cố định và không để tồn tại duplicate filters.
Một điểm rất quan trọng khác là: với tổ hợp filter vô nghĩa hoặc không có kết quả, server nên trả 404 thay vì trả 200 với một trang “không tìm thấy” mơ hồ. Đây là khác biệt lớn giữa kiểm soát crawl chuẩn và chỉ chặn nóng ở firewall. Firewall cản request xấu ngay lập tức, còn thiết kế URL và HTTP status đúng giúp crawler học được ranh giới nào là hữu ích, ranh giới nào là vô nghĩa.
Ở WooCommerce, điều này thường dẫn tới một chiến lược hợp lý hơn: chỉ để một số landing page lọc thật sự có giá trị được crawl hoặc index, còn phần lớn tổ hợp động thì hoặc chặn crawl, hoặc canonical về URL chuẩn, hoặc không đưa bot tới bằng liên kết crawlable. Khi đó bạn vừa giảm tải, vừa không để crawler đi lạc vào vô số biến thể ít giá trị.
Mẫu triển khai thực tế an toàn hơn
Nếu đang chữa cháy, hãy làm theo thứ tự. Đầu tiên, xác định chính xác mẫu URL gây tải và đo log trong vài giờ đến một ngày. Tiếp theo, bật rule challenge cho nhóm ?filter_ với traffic ngoài thị trường chính của bạn hoặc traffic có tín hiệu tự động hóa. Sau đó, xác minh các bot quan trọng như Googlebot theo đúng cách, thêm ngoại lệ cho bot thật nếu cần, rồi mới cân nhắc chuyển sang block cứng khi đã chắc rule ổn định.
Song song, hãy kiểm tra cache ở nhóm URL filter, xem có thể loại bỏ chúng khỏi việc render đắt đỏ hay không, và rà lại chiến lược crawl: robots.txt, canonical, nofollow nội bộ nếu phù hợp, chuẩn hóa thứ tự filter và trả 404 cho tổ hợp vô nghĩa. Khi hai lớp này đi cùng nhau, bạn không chỉ hạ được tải hôm nay mà còn giảm xác suất tái diễn cùng một vấn đề vào tuần sau.
Nói gọn hơn: chặn là bước đầu, quản trị URL mới là bước bền.
FAQ ngắn nhưng quan trọng
Có nên chặn toàn bộ URL chứa ?filter_ ngay lập tức không?
Không phải lúc nào cũng nên. Nếu chưa biết nhóm URL nào còn giá trị cho người dùng hoặc cho search, hãy challenge trước rồi đo. Block cứng phù hợp khi bạn đã chắc rule và website đang chịu tải nặng.
Cho qua User-Agent chứa Googlebot đã đủ an toàn chưa?
Chưa. User-Agent có thể bị giả mạo. Nếu cần miễn trừ cho Googlebot, nên xác minh bằng reverse DNS và forward DNS, hoặc dùng cơ chế verified bot khi nền tảng bảo vệ của bạn hỗ trợ.
Challenge có tốt hơn 403 không?
Thường tốt hơn ở giai đoạn đầu vì giảm rủi ro chặn nhầm browser thật. Nhưng nếu traffic xấu đã rõ mẫu, website đang quá tải hoặc endpoint đó không cần mở cho nhóm traffic đó, 403 sẽ quyết liệt hơn.
Chặn ở Cloudflare rồi có cần xử lý robots.txt và canonical nữa không?
Có. Cloudflare giúp giảm tải ở mép mạng. Robots.txt, canonical, chuẩn hóa tham số và status code đúng mới là phần giúp crawler bớt tiếp tục sinh và thử vô số faceted URLs trong dài hạn.
Kết luận
Bài gốc đúng ở chỗ chỉ ra một mẫu traffic rất thực tế và đưa ra các biện pháp ứng cứu nhanh có thể triển khai ngay. Phần cần đào sâu thêm là bản chất của vấn đề: URL filter không chỉ gây nhiều request, mà còn tạo ra một không gian crawl quá lớn, dễ làm origin mất cache, tăng query và tăng thời gian xử lý. Khi hiểu tới mức này, bạn sẽ không dừng ở việc chặn bot, mà còn siết lại cách website tạo, chuẩn hóa và cho phép crawl các URL faceted của chính mình.
.wp-post-tech{font-family:”Inter”,system-ui,-apple-system,”Segoe UI”,Roboto,Arial,sans-serif;color:#1f2937;font-size:16px;line-height:1.84;max-width:860px;margin:0 auto}.wp-post-tech .post-shell{width:100%}.wp-post-tech .post-hero{margin-bottom:1.5rem;padding:0 0 1.15rem;border-bottom:1px solid #d6e0ec}.wp-post-tech .post-title{margin:0 0 .95rem;font-size:clamp(2rem,4vw,3rem);line-height:1.08;font-weight:800;letter-spacing:-.028em;color:#0f172a}.wp-post-tech .post-subtitle{margin:0;font-size:1.07rem;line-height:1.82;color:#334155}.wp-post-tech .post-intro{margin-top:1rem}.wp-post-tech .section-block{margin-top:2.1rem}.wp-post-tech .section-title{position:relative;margin:0 0 1rem;padding-left:16px;font-size:clamp(1.45rem,2.6vw,2rem);line-height:1.22;font-weight:780;color:#0f172a}.wp-post-tech .section-title::before{content:””;position:absolute;left:0;top:.2em;bottom:.2em;width:5px;border-radius:999px;background:#2563eb}.wp-post-tech h3{margin:1.35rem 0 .72rem;font-size:clamp(1.08rem,2vw,1.32rem);line-height:1.34;font-weight:700;color:#172554}.wp-post-tech p{margin:0 0 1.08rem;color:#334155;line-height:1.84}.wp-post-tech ul,.wp-post-tech ol{margin:0 0 1.18rem 1.2rem;padding:0}.wp-post-tech li{margin-bottom:.54rem;color:#334155}.wp-post-tech strong{color:#0f172a;font-weight:700}.wp-post-tech .summary-box{margin:1.25rem 0 0;padding:1.08rem 1.12rem;border:1px solid #dbe4f0;border-radius:14px;background:#fcfdff}.wp-post-tech .faq-list{margin-top:.55rem}.wp-post-tech .faq-item{margin-bottom:.92rem;padding:1rem 1.05rem;border:1px solid #e2e8f0;border-radius:14px;background:#fff}.wp-post-tech .code-block{margin:1.4rem 0;border:1px solid #dbe4f0;border-radius:14px;overflow:hidden}.wp-post-tech .code-head{display:flex;align-items:center;justify-content:space-between;gap:12px;padding:.82rem .95rem;background:#0f172a}.wp-post-tech .code-title{color:#fff;font-size:.92rem;font-weight:700}.wp-post-tech .copy-btn{appearance:none;border:0;border-radius:10px;padding:.55rem .8rem;font-size:.82rem;font-weight:700;background:#e2e8f0;color:#0f172a;cursor:pointer}.wp-post-tech code,.wp-post-tech pre{font-family:ui-monospace,SFMono-Regular,Menlo,Consolas,monospace}.wp-post-tech pre{margin:0!important;padding:1rem 1.05rem!important;background:#f8fafc!important;color:#0f172a!important;font-size:.92rem!important;line-height:1.7!important;white-space:pre-wrap!important;word-break:break-word!important;overflow-x:auto!important}@media (max-width:767px){.wp-post-tech{font-size:15px;line-height:1.78}.wp-post-tech .post-title{font-size:clamp(1.8rem,7vw,2.35rem)}.wp-post-tech .section-title{font-size:clamp(1.3rem,5.4vw,1.7rem)}.wp-post-tech h3{font-size:clamp(1.05rem,4.5vw,1.22rem)}.wp-post-tech pre{font-size:.86rem!important}}
(function(){var blocks=document.querySelectorAll(“.wp-post-tech .code-block”);blocks.forEach(function(block){var btn=block.querySelector(“.copy-btn”);var code=block.querySelector(“code”);if(!btn||!code){return}var reset=function(text){btn.textContent=text;setTimeout(function(){btn.textContent=”Copy”},1600)};btn.addEventListener(“click”,async function(){var text=code.innerText;try{if(navigator.clipboard&&window.isSecureContext){await navigator.clipboard.writeText(text);reset(“Đã copy”);return}var area=document.createElement(“textarea”);area.value=text;area.setAttribute(“readonly”,””);area.style.position=”fixed”;area.style.left=”-9999px”;document.body.appendChild(area);area.select();document.execCommand(“copy”);document.body.removeChild(area);reset(“Đã copy”)}catch(e){reset(“Copy lỗi”)}})})})();